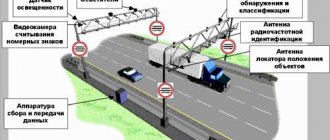
Сервис форматно-логического контроля (ФЛК) направлен на снижение регуляторных рисков по репозитарной отчетности, в том числе числа потенциальных ошибок в параметрах сделок, отчитываемых клиентами в Репозитарий.
Подключение к сервису ФЛК позволяет:
- Избежать или существенно снизить число ошибок в передаваемых сообщениях и, следовательно, сократить расходы на регистрацию данных.
- Проводить регулярный мониторинг незакрытых договоров в Реестре репозитария в срок.
- Контролировать регуляторные сроки предоставляемой информации в Репозитарий.
- Минимизировать вероятность по предоставлению недостоверной информации и соблюсти сроки предоставления информации, тем самым, избежать потенциальных санкций со стороны регулятора (часть 4 ст. 15.18 КоАП).
Вводная часть
Прием и проверку электронной отчетности в ПФР можно условно разбить на пять этапов. Каждый этап представляет собой обработку данных при помощи отдельной программы. В некоторых Управлениях передача сведений из одной программы в другую происходит автоматически. В других Управлениях (в частности, в большинстве УПФР Москвы и Московской области) инспекторы переносят данные вручную.
При любом из вариантов у каждого этапа проверки есть свои особенности, знать о которых очень полезно для бухгалтера. Расскажем подробно обо всех этапах.
Первый этап: проверка ЭЦП
Получив отчетность по телекоммуникационным каналам связи (ТКС), инспекторы, прежде всего, проверяют наличие соглашения, заключенного между Управлением фонда и страхователем, а также актуальность сертификата электронной цифровой подписи (ЭЦП).
Если программа проверки не подтвердит, что сертификат актуален и соглашение заключено, в адрес компании придет сообщение об ошибке «ЭЦП проставлена сертификатом, на который нет заключенного соглашения». Такое обычно случается с теми, кто впервые отчитывается по ТКС, а также с теми, кто недавно сменил сертификат из-за окончания срока действия, замены руководителя или по иной причине.
Сразу скажем, что повода для беспокойства нет. Такая ошибка вызвана особенностями программного обеспечения фонда, которое начинает «узнавать» ЭЦП организации только после того, как первый раз получает подписанный ею отчет. В течение четырех дней сертификат будет идентифицирован, и страхователю поступит уведомление о получении отчета. Даже если это случится за рамками отчетного периода, инспекторы не должны начислить штраф. А в следующий раз ПФР «распознает» электронную подпись уже без задержек.
Второй этап: форматно-логический контроль
Далее инспекторы проводят так называемый форматно-логический контроль. Его цель — удостовериться, что отчеты созданы без нарушения установленных форматов.
На данном этапе работники ПФР проводят проверку посредством программ CheckXML и CheckXML-UFA. Бухгалтеры тоже могут воспользоваться этими программами, чтобы перед отправкой отчетов удостовериться в их корректности. Установить проверочные программы можно самостоятельно, но тогда придется все время следить, не появилось ли обновление. В некоторые системы электронного документооборота и программы для формирования отчетности (например, в «Контур-Экстерн», который является онлайн-системой, где обновления устанавливаются без участия пользователя) они уже включены, и обновление происходит автоматически. Кстати, до 30 сентября встроенный в «Контур-Экстерн» веб-сервис будет бесплатно доступен всем желающим (см. «Страхователи могут три месяца бесплатно готовить и проверять отчеты в Контур-Отчет ПФ»).
Практика показывает, что большинство «форматных» ошибок, выявленных на этой стадии, происходит из-за изъянов бухгалтерских программ. В этом случае бухгалтеру надо обратиться к специалисту, который поддерживает программу, и договориться об устранении неполадок.
Еще одна распространенная причина ошибки — неверно указанный адрес организации или застрахованного лица. Ее удастся избежать, если установить последнюю версию классификатора адресов России (КЛАДР). Ряд систем электронного документооборота (в частности, упомянутая выше онлайн-система «Контур-Экстерн») уже содержит этот классификатор, и поддерживает его актуальность.
Проверка программы на обновления
В случае, если с документом всё в порядке, данные заполнены верно, ошибок и неточностей нет, необходимо проверить, нет ли новой версии для вашей программы 1С-Отчётность. Устаревшие модули программы могут вызывать ошибку 508. А после обновления можно продолжить работу не боясь отправлять новые отчёты. Перед проверкой и установкой новой версии рекомендуется сделать копию существующей. Так как никогда не известно наверняка, чем это может закончиться для вашего ПО.
- Выберите в открытой программе пункт «Конфигурация»;
- Наведите курсор мыши на пункт «Поддержка»;
- Справа от него появится выпадающее меню, где нужно выбрать «Обновить конфигурацию»;
- Если этот пункт неактивен в данный момент, нажмите в окне «Конфигурация» строку «Открыть конфигурацию».
Далее следует выбрать функцию, которая автоматически проверит и установит на ваш компьютер доступные версии программы. Обновление можно скачать отдельно на любой носитель. После чего через эти же параметры обновления конфигурации указать путь к ним. После обновления желательно перезагрузить программу, чтобы новые параметры вступили в силу.
Третий этап: предбазовая проверка отчетов
Суть этого этапа в том, чтобы провести экспресс-проверку отчетов и поместить их во временное хранилище.
Экспресс-проверка проводится при помощи программного комплекса ПК Perso. Он установлен в Управлениях ПФР, и доступ к нему имеют только сотрудники фонда. Что касается страхователей, то у них, к сожалению, нет возможности использовать данный софт для самоконтроля.
Perso проверяет в числе прочего наличие и номера пачек, данные по застрахованным лицам (ФИО и СНИЛС), сверяет остатки на начало расчетного периода, указанные в расчетах платежи, остатки по сведениям до 2010 года и пр.
Если ошибки не найдены, страхователю направят расписку в приеме сведений с данными инспектора, который проводил проверку. При наличии ошибок организация получит отрицательный протокол.
Затем отчеты, которые успешно прошли проверку, будут зарегистрированы в специальном журнале и переданы во временное хранилище. Здесь есть своя особенность: в хранилище не могут находиться два файла с одинаковыми именами. Это зачастую приводит к последствиям, весьма неприятным для компании. Дело в том, что если страхователь присвоит двум разным пачкам один и тот же номер, то имена файлов этих пачек тоже совпадут. Тогда файл, который передан в хранилище раньше, будет полностью стерт одноименным файлом, переданным позже. В результате в базе данных Пенсионного фонда останутся неполные сведения о страхователе, и это сильно осложнит сверку.
Предотвратить такой казус можно при помощи небольшой хитрости: в течение года присваивать номера пачек не по порядку, а так, чтобы нумерация каждого отчетного периода имела свои отличительные черты. Например, пачки за первый квартал нумеровать «101, 102, 103 …», пачки за полугодие – «202, 203, 204 …» и так далее вплоть до конца года. Такой метод не является нарушением и позволяет избежать путаницы.
Четвертый этап: проверка перечисленных платежей
Данный этап введен в 2010 году, когда на смену ЕСН пришли взносы, и у компаний и предпринимателей появилась обязанность сдавать расчеты по начисленным и уплаченным страховым взносам (формы РСВ-1, РСВ-2 и РВ-3).
На этом этапе инспектор выбирает из поступившего пакета сведений форму РСВ и загружает ее в программно-технический комплекс, который называется «Администрирование страховых взносов» (сокращенно ПТК АСВ). Там проверяются реквизиты организации и суммы перечисленных взносов, после чего сведения сохраняются в отдельной базе данных (впоследствии из этой базы они будут переданы в отдел камеральных проверок).
Здесь, как и на предыдущем этапе, при отсутствии ошибок страхователю направляется расписка в приеме сведений, а при выявлении ошибок — отрицательный протокол. Чаще всего ошибку находят в двух случаях: либо «не прошел» платеж, либо бухгалтер ошибся при заполнении расчета.
При устранении ошибок, указанных в отрицательном протоколе, необходимо выполнить одно важное правило: исправленный вариант расчета РСВ должен быть оформлен как корректировка с соответствующим порядковым номером.
Это обусловлено тем, что в базе данных сохраняются любые, даже неправильные расчеты. Следовательно, исходный вариант расчета там уже есть, а любое исправление является корректировкой.
Обратите внимание: для сведений персонифицированного учета (формы СЗВ-6-1, СЗВ-6-2, СЗВ-6-3, АДВ-6-2, АДВ-6-3 и др.) это правило не действует. Иными словами, устранив ошибки, указанные в отрицательном протоколе, бухгалтер должен направить в фонд не корректировки, а исходники этих отчетов.
Другие причины ошибки 508 ФСС
Для устранения ошибки 508 при отправке больничного проверьте правильность вводимых данных. Об этом нам хочет сказать кодом компьютерная программа. Проверке должны подлежать также числа, расчёты и дополнительная информация в электронном бланке. Некоторые значения в нём могут быть попросту пропущены, обратите на это внимание. Могут быть указаны неверные перерасчёты сумм начислений денежных средств, дней и прочих данных. Проверьте, правильно ли назначена ставка на травматизм при необходимости.
Если долгое время не удаётся решить проблему Логический контроль, попробуйте составить новый отчёт с перерасчётом данных и заполнением формы заново. На сайте ФСС есть бесплатная программа https://fss.ru/ru/fund/download/55818/, позволяющая автоматически проводить подготовку расчётов для службы. В неё можно выгрузить файл отчётов в формате xml и ввести значения. После чего скачать исправленную версию и подать снова её в качестве отчёта. Есть возможность обратиться за помощью в поддержку ФСС на сайте.
Пятый этап: разнесение индивидуальных сведений по лицевым счетам
Последний, пятый, этап заключается в том, чтобы данные из полученной и проверенной отчетности разнести по лицевым счетам застрахованных лиц, и поместить на хранение в единую электронную базу данных. Она носит название программно-технический комплекс системы персонифицированного учета (сокращенно ПТК СПУ).
Процесс представляет собой следующее: сначала инспектор выгружает данные по расчетам из ПТК АСВ, затем — пачки индивидуальных сведений из временного хранилища Perso. При этом идет сравнение начисленных и уплаченных взносов по каждому застрахованному лицу и по организации в целом. Сотрудники фонда называют это «стыковкой сведений». Как правило, стыковка занимает день или два.
Если ошибок не обнаружено, суммы, указанные в индивидуальных сведениях, поступают на лицевые счета застрахованных лиц. При этом в адрес организации никаких сообщений и уведомлений инспекторы не направляют, то есть проверка завершается «по умолчанию».
Но иногда стыковка выявляет ошибки. Приведем пример: женщина вышла замуж и сменила фамилию. При этом на предыдущих этапах проверки в базе значилась прежняя фамилия, а на момент разнесения по лицевым счетам — уже новая. Тогда на пятом этапе система не сможет идентифицировать застрахованное лицо и зафиксирует ошибку.
В такой ситуации инспекторы должны направить в компанию уведомление об устранении расхождений. Страхователю полагается внести корректировки в течение двух недель. В противном случае фонд имеет право самостоятельно устранить расхождения и сообщить об этом в организацию. Так говорится в пункте 41 инструкции о порядке ведения индивидуального учета, утвержденной приказом Минздравсоцразвития России от 14.12.09 № 987н.
Однако на практике работники фонда очень редко направляют уведомления. Вместо этого они сразу же начинают самостоятельно вносить исправления, о чем страхователь даже не догадывается. Естественно, что при формировании отчетности за следующий период организация не учитывает корректировки, сделанные фондом. При проверке следующего периода инспекторы воспринимают это как ошибку, и компания получает отрицательный протокол. Не понимая, что произошло, бухгалтеры зачастую подозревают спецоператора связи в том, что это он изменил данные в отчетах. К сожалению, предотвратить подобную ситуацию практически невозможно.
Правильно проведенная чистка данных является одним из важных условий их качества. Например, в банк данных Европейского социального исследования (European Social Survey, https://www.europeansocialsurvey.org/) от стран участниц принимаются лишь данные, прошедшие тщательную чистку. Чистку массива можно условно разделить на техническую и логическую. Техническая чистка используется для: 1) проверки вопросов с множественными альтернативами: контроль максимального / минимального количества выбранных вариантов ответа (на тот случай если количество категорий, которые необходимо выбрать установлено точно или ограничено определенным количеством); 2) проверка для вопросов этого же типа, не выбран ли вариант «Ничего из перечисленного» вместе с другими вариантами ответа; 3) правильных переходов после вопросов-фильтров. Логическая чистка – более творческая. Если в случае технической чистки исследователь может руководствоваться исключительно требованиями к заполнению анкеты, то при логической ему необходимо подключить свое воображение и знания с целью определения тех конфигураций ответов, которые в логическом смысле являются противоречивыми. Нахождение таких ситуаций обычно указывает на ошибки ввода данных или фальсификацию анкет. В первую очередь аналитику необходимо проверить отсутствие дублей анкет в массиве, то есть ввод одной анкеты два и более раза. Самый простой способ — это построение одномерного распределения по ключевому признаку (как правило это уникальный номер анкеты). Если по нему обнаружены дубли, следует удостовериться, что ответы на вопросы также идентичны, и удалить дублирующую анкету. Для проверки идентичности ответов (не по ключевому признаку, а по содержанию всех ответов) можно использовать следующий синтаксис: for (i in 1:nrow(takeData)) { check <- apply(takeData[,-70], 1, function(x) identical(x,takeData[i,-70])) if (table(check)[«TRUE»] > 1) { shortlist <- c(shortlist, which(check == T)[which(check == T) != i]) if (!i%in%shortlist) cat(«строка»,takeData[i,»keyVar»],»:», which(check == T)[which(check == T) != i], «\n») } }
Сначала преобразуем массив, требующий проверки, в матрицу «takeData» и создаем пустой вектор «shortlist». Далее с помощью цикла for() для каждой строки матрицы с помощью функции apply() проверяем ее идентичность со всеми строками (в том числе и с самой собой) этой же матрицы, а результаты записываем в виде логического вектора «check». В данном случае «-70» указывает на то, что необходимо исключить переменную с семидесятым индексом, которая является ключевым признаком (в противном случае каждое наблюдение будет уникальным). Если количество значений TRUE превышает единицу (то есть содержание строки совпадает не только само с собой, но и содержанием, по крайней мере, еще одной строки), то в вектор «shortlist» записываются номера соответствующих строк за исключением той, которая проверяется в данный момент. И если номера текущей строки нет в «shortlist», то с помощью функции cat() выводится результат, представляющий собой номер проверяемой в данный момент строки и тех строк, которые ее дублируют. Если же ответы на вопросы с одинаковыми номерами не идентичны, тогда ошибка ввода была в номере анкеты, и каждой анкете надо присвоить уникальный номер. После этого можно переходить непосредственно к чистке данных, в процессе которой аналитик формулирует ряд логических условий программными средствами. Результатом их проверки будет список с номерами анкет, в которых обнаружены логические противоречия. Когда в распоряжении исследователя находятся бумажные анкеты, он может обратиться к ним, чтобы понять, совершены ли соответствующие ошибки в процессе ввода данных оператором, и при необходимости исправить их. Также можно определить, не выделяются ли отдельные анкеты среди других по количеству ошибок. При наличии последних их можно проконтролировать, связавшись с респондентом. Кроме того стоит проверить и другие анкеты соответствующего интервьюера. Рассмотрим примеры технической (примеры 1 и 2) и логической (примеры 3 и 4) чистки. Пример 1. Вопрос с множественными альтернативами про членство в общественных и политических организациях не может одновременно содержать ответ про членство в одной или более организации(-ях) из списка и вариант ответа «Не принадлежу ни к одной». Для проверки можно использовать следующий набор команд: finalUSind$b4_sum falserows_b4 0 & finalUSind$b4_14 == 1 wrong_b4 Сначала находится общее количество выборов общественных и политических организаций по каждому респонденту, которое записывается в переменную «b4_sum». Для этого используется функция rowSums(), относящаяся к категории функций (наряду с colSums(), rowMeans(), colMeans()), предназначенных для агрегирования информации в строках или столбцах массива. Далее с помощью двух логических условий, соответствующих описанным выше условиям, создается логический вектор «falserows_b4», в котором значения TRUE соответствуют тем строкам массива, в которых выявлено логическое противоречие, а FALSE — тем, в которых не выявлено. После этого с помощью функции which() создается вектор «wrong_b4», содержащий номера только тех строк, в которых выявлено логическое противоречие. В завершении можно обратиться к этим номерам и проверить соответствующие анкеты. Пример 2. В мониторинге «Украинское общество» отсутствуют вопросы-фильтры. В то же время, при необходимости проверить правильность переходов после вопросов-фильтров, следует прописать соответствующие условия. Допустим, что респонденту, который отвечает, что не хотел бы уезжать из населенного пункта, в котором он живет, не должен задаваться вопрос о возможном направлении переезда. Суть команд такая же, как и в предыдущем случае (аналогично для третьего и четвертого примеров): falserows_i5 wrong_i5 Пример 3. Количество людей, с которыми респондент проживает в одной комнате, не должно быть больше количества людей, с которыми он проживает в одной квартире (доме). falserows_k7 finalUSind$k6 wrong_k7 Пример 4. Если в вопросе о виде занятости о, то в вопросе о размере заработной платы за последний месяц должен быть ноль. false_l3 0 wrong_l3 Чем больше переменных используется в логических условиях, тем выше вероятность нахождения ошибки ввода или выявления фальсифицированной анкеты. В то же время стоит иметь в виду, что некоторые условия логической чистки не могут прямо говорить об ошибочном, неправильном ответе. В последнем примере респондент мог сказать о своём последнем личном доходе, а не о доходе за последний месяц, или только в данном месяце он стал безработным без каких-либо источников дохода, а прошлом месяце имел доход. Кроме того, не стоит увлекаться такими «слабыми» условиями, как, например, «Люди с высшим образованием не могут быть полностью неудовлетворенными уровнем своего образования» или «Украинцы по национальности не могут исповедовать ислам». Хотя это и нестандартные ситуации, но вполне вероятные. Также следует придерживаться разумных пределов в количестве логических условий. Присутствие малой доли нелогичности в анкете вполне допустимо. Бывают ситуации, когда некоторые оценочные суждения в начале и в конце анкеты могут не совпадать, что может свидетельствовать о неопределенности мнения респондента по данному вопросу. После реализации синтаксиса и получения перечня выявленных ошибок возможны два варианта дальнейших действий: 1) обращение к бумажным анкетам по их номеру и проверка правильности введенных данных (то есть сопоставление значений в массиве и анкете), исправление значений по необходимости; 2) работа исключительно с массивом данных. Первый вариант является более предпочтительным, но тогда чистка занимает значительно больше времени. Второй вариант – менее затратный по времени, но в этом случае исследователю приходиться принимать решение об изменении значений в переменных, содержащих несоответствия, «на свой страх и риск». В завершении этой части статьи мы приводим синтаксис, который структурирует всю проделанную перед этим работу и приводит результаты к более удобному формату:
itogi <- list(«ошибка в b4» = wrong_b4, «ошибка в i5» = wrong_i5, «ошибка в k7» = wrong_k7, «ошибка в l3» = wrong_l3) inorder <- names(sort(table(unlist(itogi)),decreasing = T)) rawresult <- list() for (i in inorder) { rawresult[] <- lapply(itogi, function(x) as.numeric(i) %in% x) } letsee <- lapply(rawresult, function(x) x)
Сначала создается список «itogi» с информацией про пропуски, полученная в предыдущих четырех примерах. Далее создается вектор «inorder», в котором фиксируется порядок анкет в зависимости от количества найденых в них логических несоответствий (по убыванию). После этого создается еще один список «rawresult», в котором с помощью цикла for() и функции lapply() для каждой анкеты фиксируется наличие или отсутствие логического несоответствия в отношении каждой проверки. Наконец создается последний список «letsee», в котором для каждой анкеты остаются только те результаты, в которых зафиксированно наличие логических несоответствий. Этот финальный список может быть использован в качестве руководства для поиска и обработки анкет, попадающих под условия проверки.
Тэги: Техническая чистка данных, Логическая чистка данных, Ошибки ввода
blog comments powered by Disqus
Советы для тех, кто перешел на учет в другое Управление ПФР
В заключение отметим, что очень много проблем при проверке электронной отчетности возникает у страхователей, которые сменили адрес, а вместе с ним и Управление ПФР.
Часто сложности возникают из-за того, что бухгалтеры ошибочно полагают, будто соглашение об обмене электронными документами, заключенное с «прежним» Управлением, будет действительно и после перехода в «новое» УПФР. На самом деле при смене Управления организация должна заключить новое соглашение — ведь в противном случае Фонд не примет электронные отчеты.
Другая причина трудностей в том, что базы данных по приему сведений в каждом Управлении свои. И, в отличие от ПТК СПУ, которая является единой централизованной системой и хранит сведения обо всех лицах, базы по приему сведений содержат только те данные, которые получены в данном отдельно взятом Управлении. Получается, что если раньше организация отчитывалась в другом УПФР, то по новому месту учета данные о прежних периодах отсутствуют, и поступят они с большим опозданием.
В связи с этим мы советуем «новичкам» первую отчетность представить не по ТКС, а на бумаге или дискете. Объяснение простое: «бумажные» отчеты потребуют личного участия инспектора, которому можно дать объяснения на словах. Тогда как электронные системы проверки, не задумываясь, зафиксируют ошибку. Поэтому вновь зарегистрированным страхователям лучше познакомиться с работниками Управления и обратить их внимание на свою ситуацию.
Контрольные соотношения
Помимо проверки декларации на «внутреннюю логику», модуль НДС+ проверяет, выполняются ли в декларации контрольные соотношения.
Если логический контроль — это проверка данных по одному конкретному счету-фактуре, то контрольные соотношения — это сверка данных по определенным разделам декларации и между разделами. Поэтому, чтобы сервис мог выполнить эту проверку, нужно загрузить в НДС+ декларацию по НДС целиком, включая разделы 1-7.
Действующие контрольные соотношения утверждены приказом ФНС от 29.10.14 № ММВ-7-3/[email protected], а также приведены в письме ФНС от 23.03.2015 № ГД-4-3/[email protected]
В НДС+ реализованы практически все соотношения, которые проверяет ФНС при обработке налоговых деклараций. Несколько контрольных соотношений, которые пока находятся в разработке, есть в Экстерне. Например, сервис проверяет, чтобы:
- исчисленный и восстановленный НДС в разделах 2–6 совпадал с итоговым НДС к уплате в разделе 9;
- вычеты в разделах 3–6 не превышали сумму в разделе 8;
- сумма НДС к вычету из всех листов раздела 8 была равна итоговой сумме на последней странице раздела, а налог к уплате из всех листов раздела 9 был равен итоговой сумме на последней странице раздела;
- налоговый агент отразил вычет в разделе 8 с кодом 06 и привел исчисленный НДС по этому же счету-фактуре в разделе 9 с кодом 06.
Если у вас возникают вопросы по заполнению декларации, в частности, по контрольным соотношениям и логическому контролю, вы всегда можете задать их нашим экспертам.